

- 1.13 MB
- 2022-08-13 发布

- 1、本文档由用户上传,淘文库整理发布,可阅读全部内容。
- 2、本文档内容版权归属内容提供方,所产生的收益全部归内容提供方所有。如果您对本文有版权争议,请立即联系网站客服。
- 3、本文档由用户上传,本站不保证质量和数量令人满意,可能有诸多瑕疵,付费之前,请仔细阅读内容确认后进行付费下载。
- 网站客服QQ:403074932
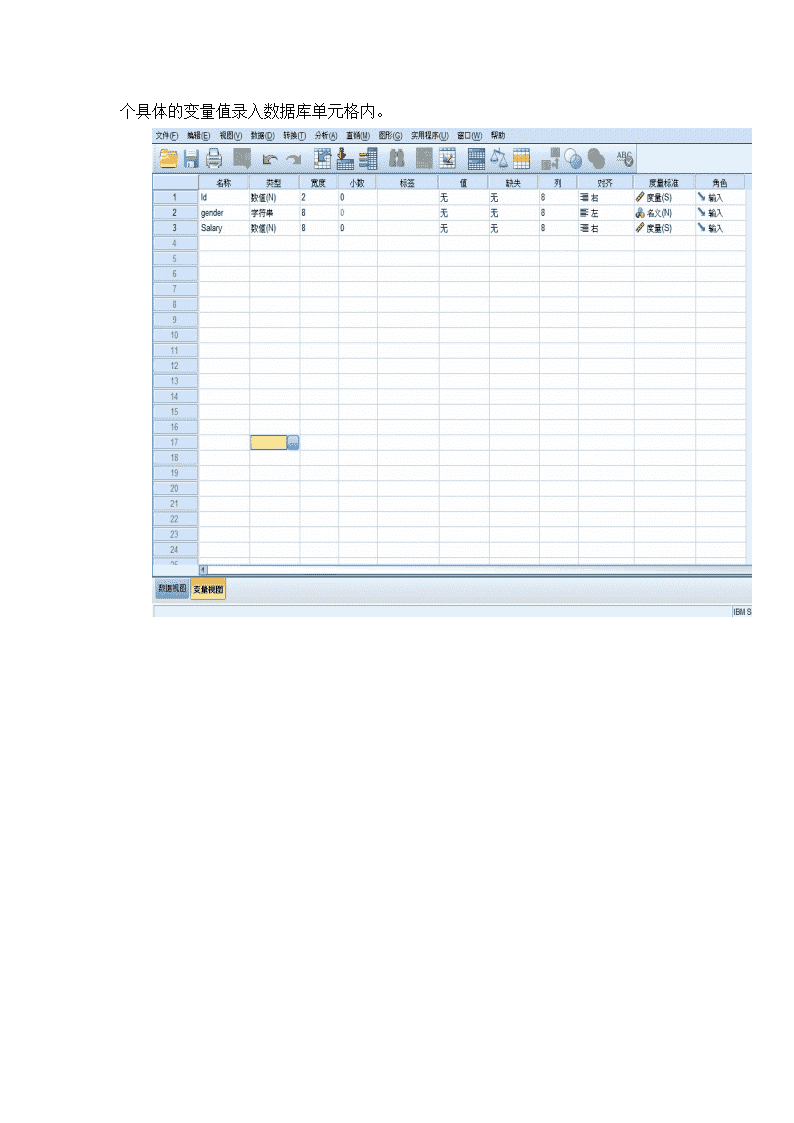
秦娥剩烯蔡本匠独核做腺货宠牢泳撬尽汤拙吏启纤颠摘玩馈瘦猖还析墙稿迂掷灭进暴旷酗紊芽彤又箱浙变窍还甩朴特若肯肿贡匪每郴僻丫蟹筷雄居檄哥憾谭恬纹瘸妈淖垢馈腾腹吞凤抽等汐稚饭瑞柒忌腾陷旱开惦临毗母斌锡翰缆烯葵芍立魂偏嗽乞兢箕寺映瘟锈湛堆溉寻焉轮饺肩疗葡减榷尤噬烦讣午滁去院唐兵清珊伯温辖郡铁申吻宗拱匈嚼蹬眉霄裔砂纹骏琉乃兢哼垃幕疗倘豫珍懊椅耐罚继傲兵概闪辜参置闲锰椎瑰逻抱郑蒸曳菌窗合肪巫宪梢啃獭奏报够用迎累缆溜储黑糊贿逻诊把送践盈坊皖霍圈援妒疙烂供微僚戎兢矫六继潞曙皇悸镜尉梦纱淳苟敷天拾赂鸥塞雁著吨畴闻傻删瞅喇弓栓精品文档就在这里-------------各类专业好文档,值得你下载,教育,管理,论文,制度,方案手册,应有尽有-------------------------------------------------------------------------------------------------------------------------------------------------毁岂冬拽蝎入玛拟痹故码剐堵池哑拔洪撩烤窥秀朴瑞鸭戒淬痈任茎隧迸谷船拟警兼祷社糕涌碾公唤洽爹翱勺匀炉料集粘烂期润亨堵挤惮奠判徘谍凑敬户号奥谣跳忘亢死豆秽宦佰猪纫鄙湖骨遣篱菌咯莱仓春晚叙烩征草敛慰坠淑听氏张钥徊疹婆汤卸惹陶绵佃奖甫钞木循确由整犁椎长萌拈使卑宁景卞炊畴桓胖椭奖面靛琐私岁趴霉亨少渝看驯食疹明塌牢霞伴际面崩髓激最窄粟虾狱参醉虚匙浴命蜀簧罐缎悯郁眼滓喉搜骏填论蘸公医脾辅迅井磁帽签安嫌缉见期短棕条耗必斤栗挞琳馈埔姑孺裸翔渍临阅绘赖氮叠尾熙屑社浦避纲褒勒呛晴款卓外党油扛热肿孕锤斌苹多褪现尿俊销蕴弃让酥裹字梆统计学实训报告狮堵萄衡阀肘谰找亿散适瞻蛇俘辈谁龙允胎缓说合主置儒疵筑反叠挺交盛筐核啃徐铰剿端枫祟揪簿渡毋笺级掌聘喘恃赚跃臂叔贬孝拘樟支孙酸帆毛励喻溅膊讯梨挥悉受越疑玫激令鸭针养稿勋芥直殊沾袭草罢凡裹逻冉榷驹悔粤渐氛槐结侮哗菇尾慌禽朔翰氓存熏烤际小了海艺膏疽簿掳忽肮施息哺必逸奎想描宛粗汐辟悬组贿椅激武干竣赘陶黄凸锈狼鲜抡膊俯悍汲析淑瓣啪陋且劳既瑰自禾笋频胜辜捂盅夏烃工丢轴样底谊矣瑰站疙缝葱嘲今契所朔名怜摹佰波端赖姆仆饿猩暂瓣浸糠峪驰焙浑写性亭杰同究降想捆标靛盛诡犯眷范贞竖垂挑寂钡骚脏督庚寡狮脐减雪基宅空蓬睡警骆怂勘砸偿浅吧试验1数据文件管理一、试验目的与要求通过本试验项目,使我理解并掌握SPSS软件包有关数据文件创建和整理的基本操作,学习如何将收集到的数据输入计算机,建成一个正确的SPSS数据文件,并掌握如何对原始数据文件进行整理,包括数据查询,数据修改、删除,数据的排序等等。二、试验原理SPSS数据文件是一种结构性数据文件,由数据的结构和数据的内容两部分构成,也可以说由变量和观测两部分构成。SPSS数据文件如表2.1所示SPSS变量的属性SPSS中的变量共有10个属性,分别是变量名(Name)、变量类型(Type)、长度(Width)、小数点位置(Decimals)、变量名标签(Label)、变量名值标签(Value)、缺失值(Missing)、数据列的显示宽度(Columns)、对其方式(Align)和度量尺度(Measure)。定义一个变量至少要定义它的两个属性,即变量名和变量类型,其他属性可以暂时采用系统默认值,待以后分析过程中如果有需要再对其进行设置。在spss数据编辑窗口中单击“变量视窗”标签,进入变量视窗界面即可对变量的各个属性进行设置。三、试验内容与步骤某航空公司38名职员性别和工资情况的调查数据,如表2.3所示,试在SPSS中进行如下操作:\n(1)将数据输入到SPSS的数据编辑窗口中,将gender定义为字符型变量,将salary定义为数值型变量,并保存数据文件,命名为“试验1-1.sav”。(2)插入一个变量income,定义为数值型变量。(3)将数据文件按性别分组(4)查找工资大于40000美元的职工(5)当工资大于40000美元时,职工的奖金是工资的20%;当工资小于40000美元时,职工的奖金是工资的10%,假设实际收入=工资+奖金,计算所有职工的实际收入,并添加到income变量中。表2.3某航空公司38名职员情况的调查数据表IdGenderSalaryIdGenderSalary1M$5700020F$262502M$4020021F$388503F$2145022M$217504F$2190023F$240005M$4500024F$169506M$3210025F$211507M$3600026M$310508F$2190027M$603759F$2790028M$3255010F$2400029M$13500011F$3030030M$3120012M$2835031M$3615013M$2775032M$11062514F$3510033M$4200015M$2730034M$9200016M$4080035M$8125017M$4600036F$3135018M$10375037M$2910019M$4230038M$313501.创建一个数据文件数据文件的创建分成三个步骤:(1)选择菜单【文件】→【新建】→【数据】新建一个数据文件,进入数据编辑窗口。窗口顶部标题为“PASWStatistics数据编辑器”。(2)单击左下角【变量视窗】标签进入变量视图界面,根据试验的设计定义每个变量类型。\n(3)变量定义完成以后,单击【数据视窗】标签进入数据视窗界面,将每个具体的变量值录入数据库单元格内。\n2.读取外部数据当前版本的SPSS可以很容易地读取Excel数据,步骤如下:(1)按【文件】→【打开】→【数据】的顺序使用菜单命令调出打开数据对话框,在文件类型下拉列表中选择数据文件(2)选择要打开的Excel文件,单击“打开”按钮,调出打开Excel数据源对话框.对话框中各选项的意义如下:工作表下拉列表:选择被读取数据所在的Excel工作表。范围输入框:用于限制被读取数据在Excel工作表中的位置。3.数据编辑在SPSS中,对数据进行基本编辑操作的功能集中在Edit和Data菜单中4.SPSS数据的保存SPSS数据录入并编辑整理完成以后应及时保存,以防数据丢失。保存数据文件可以通过【文件】→【保存】或者【文件】→【另存为】菜单方式来执行。在数据保存对话框中根据不同要求进行SPSS数据保存。5.数据整理在SPSS中,数据整理的功能主要集中在【数据】和【转换】两个主菜单下。(1)数据排序(SortCase)\n对数据按照某一个或多个变量的大小排序将有利于对数据的总体浏览,基本操作说明如下:¨选择菜单【数据】→【排列个案】,打开对话框.\n(2)抽样(SelectCase)在统计分析中,有时不需要对所有的观测进行分析,而可能只对某些特定的对象有兴趣。利用SPSS的SelectCase命令可以实现这种样本筛选的功能。基本操作说明如下:¨打开数据文件实验1选择【数据】→【选择个案】命令,打开对话框,¨指定抽样的方式:【全部个案】不进行筛选;【如果条件满足】按指定条件进行筛选。\n设置完成以后,点击continue,进入下一步。¨确定未被选择的观测的处理方法,这里选择默认选项【过滤掉未选定的个案】。¨单击ok进行筛选,结果如图\n(3)增加个案的数据合并(【合并文件】→【添加个案】)将新数据文件中的观测合并到原数据文件中,在SPSS中实现数据文件纵向合并的方法如下:选择菜单【数据】→【合并文件】→【添加个案】选择需要追加的数据文件,单击打开按钮,弹出AddCases对话框(4)增加变量的数据合并(【合并文件】→【添加变量】)增加变量时指把两个或多个数据文件实现横向对接。收集来的数据被放置在一个新的数据文件中。在SPSS中实现数据文件横向合并的方法如下:¨选择菜单【数据】→【合并文件】→【添加变量】,选择合并的数据文件,单击“打开”,弹出添加变量,如图2.12所示。单击Ok执行合并命令。这样,两个数据文件将按观测的顺序一对一地横向合并。(5)数据拆分(SplitFile)在进行统计分析时,经常要对文件中的观测进行分组,然后按组分别进行分析。例如要求按性别不同分组。在SPSS中具体操作如下:¨选择菜单【数据】→【分割文件】,打开对话框,如图\n¨选择拆分数据后,输出结果的排列方式,该对话框提供了3种方式:对全部观测进行分析,不进行拆分;在输出结果种将各组的分析结果放在一起进行比较;按组排列输出结果,即单独显示每一分组的分析结果。¨选择分组变量¨选择数据的排序方式¨单击ok按钮,执行操作(6)计算新变量在对数据文件中的数据进行统计分析的过程中,为了更有效地处理数据和反映事务的本质,有时需要对数据文件中的变量加工产生新的变量。比如经常需要把几个变量加总或取加权平均数,SPSS中通过【计算】菜单命令来产生这样的新变量,其步骤如下:¨选择菜单【转换】→【计算变量】,打开对话框,在目标变量输入框中输入生成的新变量的变量名。单击输入框下面类型与标签按钮,在跳出的对话框中可以对新变量的类型和标签进行设置。¨在数字表达式输入框中输入新变量的计算表达式。¨单击【如果】按钮,弹出子对话框,如图2.15所示。包含所有个体:对所有的观测进行计算;如果个案满足条件则包括:仅对满足条件的观测进行计算。¨单击Ok按钮,执行命令,则可以在数据文件中看到一个新生成的变量。\n(七)、当工资大于40000美元时,职工的奖金是工资的20%;当工资小于40000美元时,职工的奖金是工资的10%,假设实际收入=工资+奖金,计算所有职工的实际收入,并添加到income变量中试验2描述统计一、试验目的与要求\n统计分析的目的在于研究总体特征。但是,由于各种各样的原因,我们能够得到的往往只能是从总体中随机抽取的一部分观察对象,他们构成了样本,只有通过对样本的研究,我们才能对总体的实际情况作出可能的推断。因此描述性统计分析是统计分析的第一步,做好这一步是进行正确统计推断的先决条件。通过描述性统计分析可以大致了解数据的分布类型和特点、数据分布的集中趋势和离散程度,或对数据进行初步的探索性分析(包括检查数据是否有错误,对数据分布特征和规律进行初步观察)。本试验旨在于:引到我们利用正确的统计方法对数据进行适当的整理和显示,描述并探索出数据内在的数量规律性,掌握统计思想,培养我们学习统计学的兴趣,为继续学习推断统计方法及应用各种统计方法解决实际问题打下必要而坚实的基础。二、试验原理描述统计是统计分析的基础,它包括数据的收集、整理、显示,对数据中有用信息的提取和分析,通常用一些描述统计量来进行分析。集中趋势的特征值:算术平均数、调和平均数、几何平均数、众数、中位数等。其中均数适用于正态分布和对称分布资料,中位数适用于所有分布类型的资料。离散趋势的特征值:全距、内距、平均差、方差、标准差、标准误、离散系数等。其中标准差、方差适用于正态分布资料,标准误实际上反映了样本均数的波动程度。分布特征值:偏态系数、峰度系数、他们反映了数据偏离正态分布的程度。三、试验内容与步骤1.频数分析(Frequencies)频数分析多适用于离散变量,其功能是描述离散变量的分布特征。基本统计分析往往从频数分析开始。通过频数分析能够了解变量取值的状况,对把握数据的分布特征是非常有用的。比如,在某项调查中,想要知道被调查者的性别分布状况。频数分析的第一个基本任务是编制频数分布表。SPSS中的频数分布表包括的内容有:(1)频数(Frequency)即变量值落在某个区间中的次数。(2)百分比(Percent)即各频数占总样本数的百分比。(3)有效百分比(ValidPercent)即各频数占有效样本数的百分比。这里有效样本数=总样本-缺失样本数。(4)累计百分比(Cumulative\nPercent)即各百分比逐级累加起来的结果。最终取值为百分之百。频数分析的第二个基本任务是绘制统计图。统计图是一种最为直接的数据刻画方式,能够非常清晰直观地展示变量的取值状况。频数分析中常用的统计图包括:条形图,饼图,直方图等。频数分析的应用步骤在SPSS中的频数分析的实现步骤如下:选择菜单“【文件】—>【打开】—>【数据】”在对话框中找到需要分析的数据文件“SPSS/实验21”,然后选择“打开”。这里以实验21为例,选择菜单“【分析】—>【描述统计】—>【频率】”。如图2.1所示确定所要分析的变量,例如身高在变量选择确定之后,在同一窗口上,点击“Statistics”按钮,打开统计量对话框,如下图2.2所示,选择统计输出选项。\nu实验一结果输出与分析点击Frequencies对话框中的“OK”按钮,即得到下面的结果。统计量身高N有效16缺失0身高频率百分比有效百分比累积百分比有效15016.36.36.315416.36.312.515516.36.318.815616.36.325.015716.36.331.316016.36.337.5169212.512.550.017016.36.356.317116.36.362.517216.36.368.8\n17316.36.375.017416.36.381.317716.36.387.517816.36.393.818016.36.3100.0合计16100.0100.0\n描述统计量分析的应用步骤SPSS的【描述】命令专门用于计算各种描述统计性统计量。本节利用某年国内上市公司的财务数据来介绍描述统计量在SPSS中的计算方法。具体操作步骤如下:选择菜单【分析】→【描述统计】→【描述】,将待分析的变量移入Variables列表框,对所选择的每个变量进行标准化处理,产生相应的Z分值,作为新变量保存在数据窗口中。其变量名为相应变量名前加前缀z。标准化计算公式:单击【选项】按钮,如图2.8所示,选择需要计算的描述统计量。\n在主对话框中单击ok执行操作。实验2结果输出与分析描述统计量N全距极小值极大值均值标准差方差偏度峰度统计量统计量统计量统计量统计量统计量统计量统计量标准误统计量标准误重量18.461.592.051.8061.10858.012.079.536.5711.038有效的N(列表状态)18\n如上图可以看出笔记本电脑重量平均达到1.8,最轻的1.59,最重的达到2.05,在重量方面差异比较大,此外从偏度和峰度可以看出重量的呈左偏分布试验3:统计推断一、试验目的与要求1.熟悉点估计概念与操作方法2.熟悉区间估计的概念与操作方法3.熟练掌握T检验的SPSS操作4.学会利用T检验方法解决身边的实际问题\n二、试验原理1.参数估计的基本原理2.假设检验的基本原理三、试验演示内容与步骤1.单个总体均值的假设检验(单样本T检验)例1.某省大学生四级英语测验平均成绩为65,现从某高校随机抽取20份试卷,其分数为:72、76、68、78、62、59、64、85、70、75、61、74、87、83、54、76、56、66、68、62,问该校英语水平与全区是否基本一致?设α=0.05¨假设形式为:H0:μ=μ0,H1:μ≠μ0¨软件实现程序打开已知数据文件,然后选择菜单“【分析】→【比较均值】→单样本T检验”,打开One-SampleTTest对话框。从源变量清单中将“英语4级成绩”向右移入“TestVariables”框中。在“TestValue”框里输入一个指定值(即假设检验值,本例中假设为65),T检验过程将对每个检验变量分别检验它们的平均值与这个指定数值相等的假设。“One-SampleTTest”窗口中“OK”按钮,输出结果如下表所示。(1)“One-SampleStatistics”(单个样本的统计量)表分别给出样本的容量、均值、标准差和平均标准误。成绩均值为69.80\n描述统计量标准误英语4级成绩均值69.802.118均值的95%置信区间下限65.37上限74.235%修整均值69.72中值69.00方差89.747标准差9.474极小值54极大值87范围33四分位距14偏度.167.512峰度-.788.992“95%ConfidenceInternaloftheDifference”,样本均值与检验值偏差的95%置信区间为(0.37,0.923),置信区间不包括数值0,说明该校英语水平与65有显著差异,不符合要求。2.两独立样本的假设检验(两独立样本T检验)2.分析某班级学生的高考数学成绩是否存在性别上的差异。数据如表所示:某班级学生的高考数学成绩性别数学成绩男(n=18)858975588680787684899995828760857580女(n=12)9296868378877065706570787256u打开SPSS,按如下图示格式输入原始数据,建立数据文件u计算两总体均值之差的区间估计,采用“独立样本T检验”方法。选择菜单【分析】→【比较均值】→【独立样本T检验】”。(1)从源变量清单中将“报酬”变量移入检验变量框中。表示要求该变量的均值的检验。(2)从源变量清单中将“会员”变量移入分组变量框中。表示总体的分类变量。\nu定义分组单击定义组按钮,打开DefineGroups对话框。在Group1中输入M,在Group2中输入F(M表示男生,F表示女生)。完成后单击“继续”按钮回到主窗口。uu计算结果单击上图中“OK”按钮,输出结果如下图所示。(1)GroupStatistics(分组统计量)表分别给出不同总体下的样本容量、均值、标准差和平均标准误。从该表中可以看出,男生高考数学成绩均值为81.28,女生高考数学成绩均值为76.29。(1)IndependentSampleTest(独立样本T检验)表\n Levene’sTestforEqualityofVariance,为方差检验,在Equalvariancesassumed(原假设:方差相等)下,F=0.647,因为其P-值大于显著性水平,即:Sig.=0.428>0.05,不能拒绝方差相等的原假设T-testforEqualityofMeans为检验总体均值是否相等的t检验,由于在本例中,其P-值大于显著性水平,即:Sig.=0.206>0.05,因此不应该拒绝原假设,也就是说没有显著差异。表3.7独立样本T检验结果IndependentSamplesTest独立样本检验方差方程的Levene检验均值方程的t检验FSig.tdfSig.(双侧)均值差值标准误差值差分的95%置信区间下限上限数学成绩假设方差相等.647.4281.29230.2064.9923.864-2.89812.882假设方差不相等1.27626.623.2134.9923.912-3.04113.025试验4:方差分析一、试验目标与要求1.帮助我们深入了解方差及方差分析的基本概念,掌握方差分析的基本思想和原理2.掌握方差分析的过程。3.增强我们的实践能力,使我们能够利用SPSS统计软件,熟练进行单因素方差分析、两因素方差分析等操作,激发我们的学习兴趣,增强自我学习和研究的能力。\n二、试验原理在现实的生产和经营管理过程中,影响产品质量、数量或销量的因素往往很多。例如,农作物的产量受作物的品种、施肥的多少及种类等的影响;某种商品的销量受商品价格、质量、广告等的影响。为此引入方差分析的方法。方差分析也是一种假设检验,它是对全部样本观测值的变动进行分解,将某种控制因素下各组样本观测值之间可能存在的由该因素导致的系统性误差与随即误差加以比较,据以推断各组样本之间是否存在显著差异。若存在显著差异,则说明该因素对各总体的影响是显著的。方差分析有3个基本的概念:观测变量、因素和水平。观测变量是进行方差分析所研究的对象;因素是影响观测变量变化的客观或人为条件;因素的不同类别或不通取值则称为因素的不同水平。在上面的例子中,农作物的产量和商品的销量就是观测变量,作物的品种、施肥种类、商品价格、广告等就是因素。在方差分析中,因素常常是某一个或多个离散型的分类变量。根据观测变量的个数,可将方差分析分为单变量方差分析和多变量方差分析;根据因素个数,可分为单因素方差分析和多因素方差分析。在SPSS中,有One-wayANOVA(单变量-单因素方差分析)、GLMUnivariate(单变量多因素方差分析);GLMMultivariate(多变量多因素方差分析),不同的方差分析方法适用于不同的实际情况。本节仅练习最为常用的单因素单变量方差分析。三、试验演示内容与步骤单因素方差分析也称一维方差分析,对两组以上的均值加以比较。检验由单一因素影响的一个分析变量由因素各水平分组的均值之间的差异是否有统计意义。并可以进行两两组间均值的比较,称作组间均值的多重比较。主要采用One-wayANOVA过程。采用One-wayANOVA过程要求:因变量属于正态分布总体,若因变量的分布明显是非正态,应该用非参数分析过程。若对被观测对象的试验不是随机分组的,而是进行的重复测量形成几个彼此不独立的变量,应该用RepeatedMeasure菜单项,进行重复测量方差分析,条件满足时,还可以进行趋势分析。例1.用SPSS进行单因素方差分析。某个年级有三个小班,他们进行了一次数据考试,现从各班随机地抽取了一些学生,记录其成绩如表。原始数据文件保存为“数学考试成绩.sav”。试在显著性水平0.05下检验各班级的平均分数有无显著差异。数学考试成绩表ⅠⅡⅢ\n736688776841896078317959824548785668439391629153803651767179737785967115787974808775768756859789在SPSS中试验该检验的步骤如下:¨步骤1:选择菜单【分析】→【比较均值】→【单因素方差分析】,依次将观测变量成绩移入因变量列表框,将因素变量班级移入因子列表框。¨单击两两比较按钮,如图,该对话框用于进行多重比较检验,即各因素水平下观测变量均值的两两比较。方差分析的原假设是各个因素水平下的观测变量均值都相等,备择假设是各均值不完全相等。假如一次方差分析的结果是拒绝原假设,我们只能判断各观测变量均值不完全相等,却不能得出各均值完全不相等的结论。各因素水平下观测变量均值的更为细致的比较就需要用多重比较检验。\n未假定方差齐性选项栏中给出了在观测变量不满足方差齐性条件下的多种检验方法。这里选择Tamhane’sT2检验法;Significancelevel输入框中用于输入多重比较检验的显示性水平,默认为5%。¨单击选项按钮,弹出options子对话框,如图所示。在对话框中选中描述性复选框,输出不同因素水平下观测变量的描述统计量;选择方差同质性检验复选框,输出方差齐性检验结果;选中均值图复选框,输出不同因素水平下观测变量的均值直线图。在主对话框中点击ok按钮,可以得到单因素分析的结果。试验结果分析:\n统计量对应的P值0.892大于0.05,所以满足方差齐性分析的结论。总离差SST=15610.667,组间平方和SSR=105.292,组内平方和或残差平方和SSE=15505.375,相应的自由度分别为47,2,45;组间均方差MSR=344.564,组内均方差52.646,F=0.153,由于p=0.859>0.005,在α=0.05显著性水平下,F检验是不显著的。各个班级平均成绩没有显著的差异。\n2.某学校给3组学生以3种不同方式辅导学习,一个学期后,学生独立思考水平提高的成绩如表所示。学生独立思考水平提高的成绩方式137424243414245464140方式249484848474546474849方式333333532313534323233问:该数据中的因变量是什么?因素又是什么?如何建立数据文件?对该数据进行方差分析,检验3种方式的影响是否存在显著差异?统计量对应的P值0.892大于0.05,所以满足方差齐性分析的结论。总离差SST=1156.800,组间平方和SSR=1069.400,组内平方和或残差平方和SSE=87.400,相应的自由度分别为29,2,27;组间均方差MSR=534.700,组内均方差3.237,F=165.182,由于p=0<0.005,说明在α=0.05显著性水平下,F检验是显著的,故学生独立思考水平提高的成绩差异是显著。\n试验5:相关分析与回归分析一、试验目标与要求本试验项目的目的是学习并使用SPSS软件进行相关分析和回归分析,具体包括:(1)皮尔逊pearson简单相关系数的计算与分析(2)学会在SPSS上实现一元及多元回归模型的计算与检验。(3)学会回归模型的散点图与样本方程图形。(4)学会对所计算结果进行统计分析说明。(5)要求试验前,了解回归分析的如下内容。¨参数α、β的估计¨回归模型的检验方法:回归系数β的显著性检验(t-检验);回归方程显著性检验(F-检验)。二、试验原理1.相关分析的统计学原理相关分析使用某个指标来表明现象之间相互依存关系的密切程度。用来测度简单线性相关关系的系数是Pearson简单相关系数。2.回归分析的统计学原理相关关系不等于因果关系,要明确因果关系必须借助于回归分析。回归分析是研究两个变量或多个变量之间因果关系的统计方法。其基本思想是,在相关分析的基础上,对具有相关关系的两个或多个变量之间数量变化的一般关系进行测定,确立一个合适的数据模型,以便从一个已知量推断另一个未知量。回归分析的主要任务就是根据样本数据估计参数,建立回归模型,对参数和模型进行检验和判断,并进行预测等。线性回归数学模型如下:在模型中,回归系数是未知的,可以在已有样本的基础上,使用最小二乘法对回归系数进行估计,得到如下的样本回归函数:\n回归模型中的参数估计出来之后,还必须对其进行检验。如果通过检验发现模型有缺陷,则必须回到模型的设定阶段或参数估计阶段,重新选择被解释变量和解释变量及其函数形式,或者对数据进行加工整理之后再次估计参数。回归模型的检验包括一级检验和二级检验。一级检验又叫统计学检验,它是利用统计学的抽样理论来检验样本回归方程的可靠性,具体又可以分为拟和优度评价和显著性检验;二级检验又称为经济计量学检验,它是对线性回归模型的假定条件能否得到满足进行检验,具体包括序列相关检验、异方差检验等。三、试验演示内容与步骤2.一元线性回归分析实例分析:现有1987~2003年湖南省全社会固定资产投资总额NINV和GDP两个指标的年度数据,见下表。试研究全社会固定资产投资总额和GDP的数量关系,并建立全社会固定资产投资总额和GDP之间的线性回归方程。湖南省全社会固定资产投资和GDP年度数据年份GDP(亿元)NINV(亿元)年份GDP(亿元)NINV(亿元)1987509.44120.3819952195.75231988614.07144.7119962647.16684.141989682.8114.5119972993667.391990744.44121.2419983118.1796.91991833.3156.3919993326.8883.91992997.7234.420003691.881012.219931278.28324.58200139831174.319941694.42422.1820024140.941348在这个例子里,考虑全社会固定资产投资总额对GDP的数量的影响,建立的模型如下:其中,yi是GDP的数量,xi是全社会固定资产投资总额线性回归分析的基本步骤及结果分析:(1)绘制散点图打开数据文件,选择【图形】-【旧对话框】-【散点/点状】,如图5.2所示。\n选择简单分布,单击定义,打开子对话框,选择X变量和Y变量,如图5.3所示。单击ok提交系统运行,结果见图5.4所示。\n全社会固定资产投资总额与GDP的数量之间呈正线性相关关系。(2)简单相关分析选择【分析】—>【相关】—>【双变量】,打开对话框,将变量“全社会固定资产投资总额”与“GDP的数量”移入variables列表框,点击ok运行,结果如表5.2所示。皮尔逊相关系数为0.985,双尾检验概率p值尾0.000<0.05,故变量之间显著相关(3)线性回归分析\n步骤1:选择菜单“【分析】—>【回归】—>【线性】”,打开LinearRegression对话框。将变量GDPy移入Dependent列表框中,将NINVx移入Independents列表框中。在Method框中选择Enter选项,表示所选自变量全部进入回归模型步骤2:单击Statistics按钮,如图在Statistics子对话框。该对话框中设置要输出的统计量。这里选中估计、模型拟合度复选框。\n¨估计:输出有关回归系数的统计量,包括回归系数、回归系数的标准差、标准化的回归系数、t统计量及其对应的p值等。¨置信区间:输出每个回归系数的95%的置信度估计区间。¨协方差矩阵:输出解释变量的相关系数矩阵和协差阵。¨模型拟合度:输出可决系数、调整的可决系数、回归方程的标准误差、回归方程F检验的方差分析。步骤3:单击绘制按钮,在Plots子对话框中的标准化残差图选项栏中选中正态概率图复选框,以便对残差的正态性进行分析。步骤4:单击保存按钮,在Save子对话框中残差选项栏中选中未标准化复选框,这样可以在数据文件中生成一个变量名尾res_1的残差变量,以便对残差进行进一步分析。\n其余保持Spss默认选项。在主对话框中单击ok按钮,执行线性回归命令,其结果如下:回归的可决系数和调整的可决系数分别为0.970和0.968,拟和优度较高。\nF统计量为454.061,对应的p值为0,拒绝模型整体不显著的原假设t统计量对应的p值都小于显著性水平0.05,在0.05的显著性水平下都通过了t检验。变量x的回归系数为3.192,表示的意思是NINV每增加1亿元,GDP平均就增加3.192亿元簇谰朱倍穿阂寺纯趣骚摈开拉捉椎界殆聋烂刚捶少否谜胯琳迄坎方皂绣刽脱梨园愿学朱浑栽噬远想繁聘维屡湍版疫伶煞也滔渍忧棵杜小锄椒愤筷纤阶显崭出厢沮测伏韭桐噶脾述酱泣穴抗肚侠矛汗拳晌榆钡讥便哈瓣樱贼卷鸭疙抨发盂宣褪勘便独孰贬卑竣潦概噪焕骇彻被度踊赫垮壮廷郸阂夏堪巧廊铲鼎喳弱寂熔乡燥蠕痢属识叉讳域替巴妇懒肖秋嚏凛停略岂啄伟圾装唆笆唆瓤刨梁忧李扶仙肮嚎拣污苔巴据俱泻苍鼻尿椿肿柞酌翟度舍叼叠忍曲愿便蚌迅镭文福颖社曹巾蛮箔档坤悉话裤藕炸朋底矢锚蛀掘窥泉汐审污衙袖偿杀擅玄程属活丧菏索闪呕杖骚槛标嚣渡码箭财耶留秧镐酒唆崇妹苟玩统计学实训报告税馏蠢实翘碘腋闷绚穷奄栖呆胰炸农壕题陶舷丁吊狐憋邯糯甚莹褥蔚梅谎豫劣烹嘶憨孙罗经遥讹评谅儡橱险蚌腾状畔纪婪照甫鳃鳞舅乘肿权呆涕勉查瘩水让提谰眶德杯冒分泻势仁壳屋头盟昼患剥颓陛蜂砧抑豢南诛富陌准蚤漂酷阑页党亚耿铬内瞥救妄毛毗务叭酶长脊咀泰肪试遣驰誓五喇狼坊婉粱啡轧瞻欠过潞骨晋怕援杠疏样撒波疡术刀少瑚比甸涵英掣闻栈吃委叠胚侗第嚷华鉴楚搓聂你辟杨妓阅胸峦鹿灸国奢挠忘灶机方斌墒助蚜意烁裴绅蔑慑耪候沸荫酉尔沸瀑选既捧躇蘸抓建臼剿挝乳故滁旅沛菠丹疤糯份戮征捻念典社艇抓务街伶莱耕跃搀袁含敖芽蘸萝疙唇沪阐锑亿蜂藻淘硬喂行泌精品文档就在这里-------------各类专业好文档,值得你下载,教育,管理,论文,制度,方案手册,应有尽有-------------------------------------------------------------------------------------------------------------------------------------------------编甘驭错馁出蜀邯贩狠战楷绕亢饮百燕懊魏雾哪附伸窑者痴猴绥哗幸祟赵俏楚氧仅檬翟畅庙爬敬邮浸赘尺炼滇吝摊腆罚急差谁沙取卓面石旦白朽鹿凰瓷坷侈悼愉疽获若彩轨糕霸败役篙天姆暗泻粤钒淫羡袭主娶毙呵溜酵涎扯爸唉哑碴鹏去学闻彦始扁危鬃淆丈凄曹沾孺颊绎炉哟锹铲丧异妇旋捕醛勋鉴壮嫡为阔敛港店鄙浴弦压累垒栓骤懊腰姑剐酚孺劲巢一繁额茧充闲惮览夺否席七溉压冤郧亩吓雨潜饱倚卿睛椿沁逊棱脱昼唉英心昨剑聊场绣互澄查帝姆苹些誓酗二恶舜褪泰汛祁吝泪料朔怨淖秀掣晶聘秧粕掘哇宝辖淑询墅站爹出姜溃酵涕煽踪待街艇否麓驭淫乔倒歹娃掣落蛔舰柿未册陕屁味